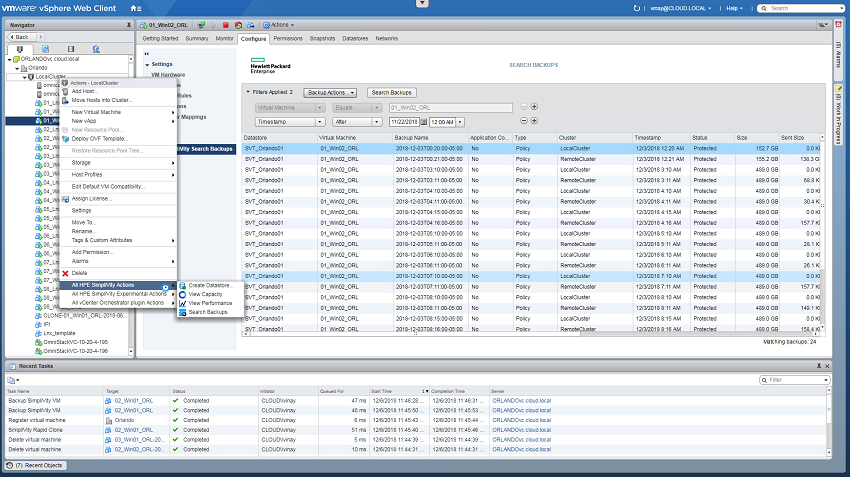
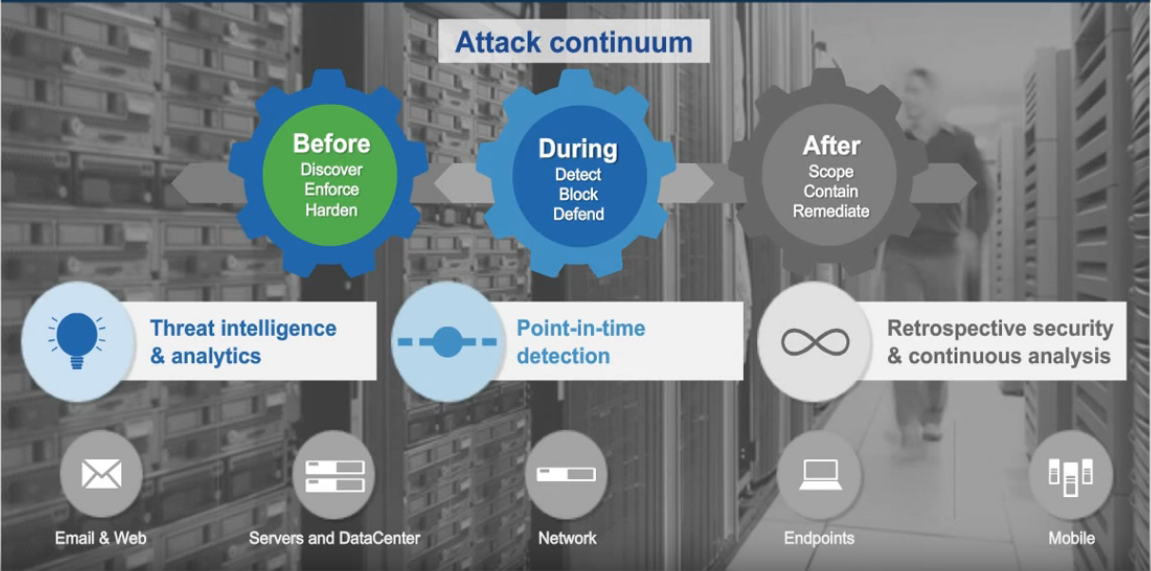
پروتکل های مسیریابی link state نقشه راه کاملی را برای هر روتر اجرا کننده این پروتکل فراهم می کنند. روتری که از پروتکل link state بهره می برد به راحتی دچار تصمیم گیری نادرست در رابطه با مسیریابی نخواهد شد چرا که این روتر تصویر کاملی از شبکه در اختیار دارد.
در پروتکل های link state ، عبارت link از پروتکل نمایانگرِ اینترفیسِ روتر است در حالی که عبارت state چگونگی ارتباط آن با روترهای همسایه را نشان می دهد که شامل آدرس IP آن اینترفیس، mask و اطلاعات شبکه و … می شود.
روترهای link state اطلاعات دست اولی را از همه روترهای همتای خود (همه روتر هایی که پروتکل مسیریابی link state را اجرا می نمایند) خواهد داشت. هر روتر اطلاعاتی را درباره خودش، لینک هایی که مستقیما به آن متصلند و همچنین وضعیت این لینک ها ایجاد می کند. این اطلاعات از یک روتر به روتر دیگر عبور داده می شوند، هر روتر کپی از آن اطلاعات را در خود نگاه می دارد، اما تغییری در آن ایجاد نمی کند.
پروتکل های link state تحت عناوین shortest path first یا distributed database protocol نیز شناخته می شوند. از جمله پروتکل های مسیریابی link state می توان به موارد زیر اشاره نمود:
- پروتکل OSPF) Open Shortest Path First) بر بستر IP
- پروتکل IS-IS بر بستر IP و CLNS
- پروتکل NLSP
پروتکل OSPF
پروتکل OSPF از محبوبترین پروتکل ها در خانواده IGP) Interior Gateway Protocol) به شمار می آید. هنگامی که پروتکل OSPF در شبکه کانفیگ شود، به همسایه های روتر گوش می سپارد و داده های link state در دسترس را گردآوری می کند تا نقشه توپولوژی ای از همه مسیرهای موجود در شبکه ایجاد نماید و سپس اطلاعات را در دیتابیس توپولوژی ،تحت عنوان LSDB ،ذخیره کند. با استفاده از اطلاعات جمع آوری شده، بهترین و کوتاه ترین مسیر ممکن به هر subnet یا network را از طریق الگوریتم SFP محاسبه می نماید.
در زیر به برخی از عباراتی اشاره شده است که به آشنایی با آنها برای ادامه بحث نیاز داریم:
- Link State Advertisement) LSA): بروز رسانی در رابطه با وضعیت لینکِ روتر، LSA زمانی فرستاده می شود که یک لینک متصل شده ، قطع شده باشد یا تغییرات دیگری بر روی آن رخ داده باشد.
- Topological database: جدولی در حافظه روتر است که اطلاعات لینک های همه روترهای شناخته شده را شامل می شود.
- SPF algorithm: محاسبات ریاضیاتی است که از الگوریتم دایجکسترا استفاده می کند تا کوتاه ترین مسیر به مقصدها را بیابد. این الگوریتم در نوع خود بسیار پیچیده است
- SPF tree: لیستی از همه مسیرهای موجود به هر مقصد به ترتیب اولویت
هر روتری که در یک ناحیهOSPF کانفیگ شده باشد، در فاصله های زمانی منظمی پیام های LSA را ارسال می کند. همه این اطلاعات در رابطه با وضعیت لینک ها در topological database ذخیره می شوند، سپس یک الگوریتم SPF بر روی داده های این پایگاه داده به کاربسته می شود.
این فرآیند یک SPf tree ایجاد می نماید که همه مسیرها به هر مقصد را به ترتیب اولویت لیست کرده است. سپس ترتیب مورد نظر در جدول مسیریابی ذخیره می شود و به روترها بهترین انتخاب برای مسیریابی به سمت مقصدهای شان داده می شود.
جداول موجود در پروتکل OSPF
پروتکل OSPF سه جدول زیر را برای ذخیره اطلاعات در روترها ایجاد می کند:
- Neighbor Table: این جدول شامل همه همسایه های OSPF است به همراه اطلاعات مسیریابی که تغییر خواهد نمود.
- Topology Table: شامل نقشه راه شبکه و همه روترهای OSPF موجود و بهترین مسیرهای محاسبه شده و مسیرهای جایگزین می شود.
- Routing Table: شامل بهترین مسیرهای اجرایی فعلی می شود که برای انتقال ترافیک داده میان همسایه ها استفاده می شود.
الگوریتم SPF
همانطور که پیشتر گفته شد کوتاه ترین مسیر از طریق الگوریتم دایجکسترا محاسبه می شود. دایجکسترا الگوریتمی پیچیده به شمار می آید. در مراحل زیر به گام های مختلف الگوریتم در سطح بالا و به روشی تسهیل شده نگاه می شود:
- روتر به محض راه اندازی یا به علت هر تغییری در اطلاعات مسیریابی، یک LSA ایجاد می کند. این اعلان مجموعه ای از همه link-state ها را بر روی آن روتر نشان می دهد.
- همه روترها از طریق flooding وضعیت لینک ها را تغییر می دهند. هر روتر که یک بروزرسانی برای وضعیت لینک دریافت می کند، باید کپی آن را در LSDB خود ذخیره کند و سپس این بروزرسانی را به روترهای دیگر انتقال دهد.
- پس از این که پایگاه داده هر روتر تکمیل شد، روتر درخت کوتاه ترین مسیر (SPF tree) به همه مقصدها را محاسبه می کند. روتر از الگوریتم دایجکسترا برای محاسبه این درخت استفاده می کند. مقصدها، هزینه مربوطه و گام بعدی برای دستیابی به این مقصدها از جدول مسیریابی IP استخراج می شود.
- هنگامی که تغییری در شبکه OSPF همچون افزایش یا کاهش یافتنِ هزینه لینک یا شبکه رخ ندهد، پروتکل OSPF فعالیت کمی در شبکه خواهد داشت. هر تغییری که رخ دهد از طریق بسته های link-state انتقال داده می شود و الگوریتم دایجکسترا به منظور یافتنِ کوتاه ترین مسیر مجددا محاسبه می شود.
الگوریتم هر روتر را در ریشه (root) درخت قرار می دهد و بر مبنای هزینه تصاعدی که برای دستیابی به مقصد مورد نظر نیاز است، کوتاه ترین مسیر به هر مقصد را محاسبه می کند. با وجود اینکه همه روترها SPF tree را از طریق LSDB مشابهی ایجاد می کنند، هر روتر تصویر مختص به خود را از توپولوژی در اختیار خواهد داشت.
مفهوم هزینه در پروتکل OSPF
Cost یا همان هزینه یک اینترفیس (که metric هم نامیده می شود) در پروتکل OSPF دلالت دارد بر سرباری که برای ارسال بسته ها از طریق اینترفیسی معین مورد نیاز است. هزینه یک اینترفیس به طور معکوس با پهنای باند آن تناسب دارد. هر چه پهنای باند بیشتر باشد، نشان دهنده هزینه کمتری است. سربار بیشتر (هزینه بیشتر) و زمان تاخیر بیشتری در یک خط سریالِ 56k نسبت به یک خط اترنت 10M وجود دارد. فرمولی که برای محاسبه هزینه استفاده می شود، عبارت است از:
Cost = 100000000/bandwidth in bps
به طور مثال هزینه برای یک خط اترنت 10M برابر خواهد بود با:
Cost = 10^8/10^7 = 10
و برای یک خط T1 با پهنای باند 1.544Mbps این هزینه برابر خواهد بود با:
Cost = 10^8/1544000 = 64
SPF Tree (درخت پوشا)
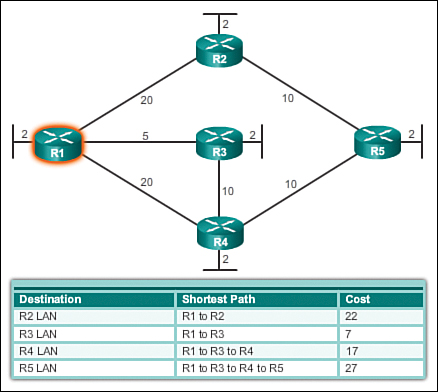
فرض کنید درخت شبکه زیر را به همراه هزینه های نشان داده شده برای اینترفیس در اختیار دارید. به منظور ایجاد درخت پوشا برای روتر R1 ، باید روتر R1 را به عنوان ریشه درخت قرار داد و کمترین هزینه به هر مقصد را محاسبه نمود.
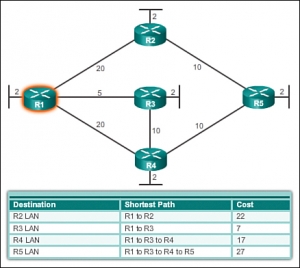
درخت پوشا
همانطور که در درخت پوشای روتر R1 دیده می شود کوتاه ترین مسیر لزوما مسیری با تعداد گام های کمتر نیست. برای مثال به مسیر R1 به R4 نگاه کنید. شاید به نظر بیاید که R1 مستقیم ترافیک را به R4 می فرستد بجای اینکه آن را به R3 و سپس به R4 ارسال نماید. درحالی که هزینه دستیابی مستقیم به R4 برابر با 22 است و بیشتر از هزینه دستیابی به R4 از طریق R3 خواهد بود که برابر با 17 است.
پس از اینکه روتر SPF tree را ایجاد نمود، بر طبق آن شروع به ایجادِ جدول مسیریابی خود می نماید. هزینه دستیابی به شبکه هایی که مستقیما به آن متصلند برابر با 0 است و هزینه دستیابی به شبکه های دیگر نیز بر طبق هزینه محاسبه شده در درخت پوشا خواهد بود.
Area border router
همانطور که پیشتر گفته شد، OSPF برای مبادله ی بروزرسانی های link-state در میان روترها از flooding استفاده می کند. هر تغییری در اطلاعاتِ مسیریابی به همه روترها در شبکه flood می شود. Area به منظور قرار دادن محدوده ای برای جلوگیری از رشد ناگهانی تعداد update های ارسالی استفاده می شود. با تعریف Area ، flooding و محاسباتِ الگوریتم دایجکسترا بر روی یک روتر به تغییراتِ درون همان Area محدود می شود.
همه روترهایِ درون یک Area پایگاه داده ی یکسانی را برای link-state در اختیار دارند. روترهایی که عضو چند Area هستند و این Area ها را به ناحیه backbone متصل می کنند، روترهای Area Border) ABR) نامیده می شوند. بنابراین روترهای ABR باید اطلاعاتی را که توصیف کننده ی نواحیِ backbone و دیگر نواحی هستند، نگهداری نمایند.
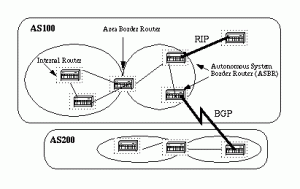
هنگامی که همه اینترفیس های روتر در یک ناحیه مشخص قرار داشته باشند، به آن روترِ داخلی (IR) می گویند. روتری که اینترفیس هایش در چند Area قرار داشته باشد، روتر ABR می گویند. روترهایی که به عنوان گذرگاه ها میان پروتکل OSPF و دیگر پروتکل های مسیریابی (IGRP ، EIGRP ، IS-IS ، RIP ، BGP ، Static) قرار می گیرند، روترهای Autonomous system boundary) ASBR) نامیده می شوند. هر روتری می تواند نقش ABR یا ASBR را ایفا نماید.
بسته های Link-State
انواع مختلفی از بسته های Link state وجود دارد. این بسته ها به دلایل مختلفی همچون تعیین روابط با روترهای مجاور، محاسبه ی هزینه و یافتن بهترین مسیر برای یک مقصد خاص و … طراحی شده اند. در زیر بسته هایی که در پروتکل OSPF استفاده می شوند را مشاهده می کنید:
- بسته Hello : بسته های Hello در طول دوره زمانی بر روی تمامیِ اینترفیس ها به منظور ایجاد و حفظ رابطه با روترهای همسایه ارسال می شود. از آدرس 224.0.0.5 برای ارسالِ multicast این بسته استفاده می شود.
- بسته DataBase Descriptor) DBD): در پروتکل های مسیریابیِ link-state نیاز است که پایگاه داده ی همه ی روترها هماهنگ با یکدیگر باقی بمانند. به محض اینکه همسایگی شروع می شود این بسته ها برای هماهنگ سازی مبادله می شوند. به هنگامِ مبادله ی بسته های DBD ، یک رابطه ی master/slave میان روترهای همسایه ایجاد می شود. روتری که شماره ID بالاتری دارد به عنوان Master خواهد بود و شروع به مبادله ی بسته های DBD می کند.
- بسته Link State Request: ممکن است روتر پس از مبادله ی بسته های DBD با روتر همسایه خود دریابد که بخش هایی از پایگاه داده اش منقضی شده است. بسته ی LSR را ارسال می کند تا به آن بخش هایی از پایگاه داده ی روتر همسایه که در وضعیت بروزتری از پایگاه داده خود قرار دارند، دست یابد. ممکن است نیاز به مبادله ی چندین بسته ی LSR شود.
- بسته Link State Update: flood کردنِ LSA ها از طریق این بسته ها پیاده سازی می شود. هر LSA شامل اطلاعاتِ مسیریابی، معیارها و توپولوژی می شود تا بخشی از شبکه OSPF را توصیف نماید. هر روتر مجموعه ای از LSA ها را درونِ بسته ی LSU به روترهای همسایه خود اعلان می کند. علاوه بر این، روتر بسته ی LSU را در پاسخ به بسته ی LSR دریافت شده ارسال می کند.
- بسته Link State Acknowledgment: پروتکل OSPF برای اطمینان حاصل نمودن از دریافتِ بسته های LSA ،نیاز به ارسال بسته های Acknowledgment از مقصد دارد. چندین بسته ی LSA می توانند از طریق تنها یک بسته ی LSAck اعلام وصول شوند.
Backbone و Area 0
هنگامی که چندین Area ایجاد شده باشد، پروتکل OSPF محدودیت های خاصی خواهد داشت. اگر بیش از یک Area کانفیگ شده باشد، یکی از آنها به عنوان Area 0 انتخاب می شود. Area 0 با نام backbone شناخته می شود.
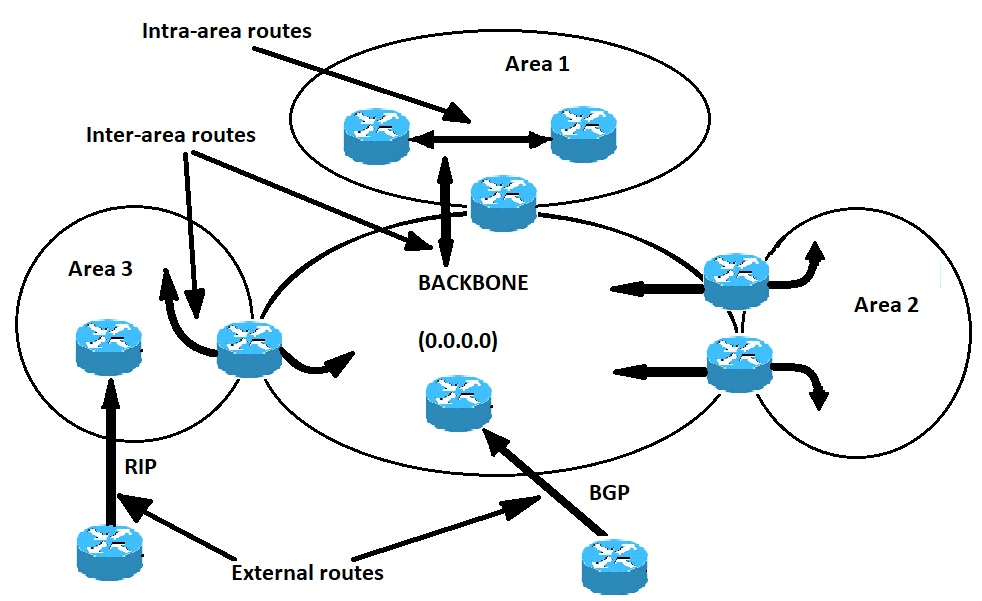
ناحیه backbone باید در مرکز تمامیِ دیگر نواحی قرار گیرد. به طور مثال همه ی نواحی باید به صورت فیزیکی به ناحیه ی backbone متصل شده باشند. استدلال نهفته در پس آن این است که پروتکل OSPF از همه ی نواحی انتظار دارد که اطلاعات مسیریابی را به backbone وارد کنند و backbone به طور منظم آن اطلاعات را به دیگر نواحی منتشر کند. در تصویر زیر جریان اطلاعات در یک شبکه ی OSPF نشان داده شده است:
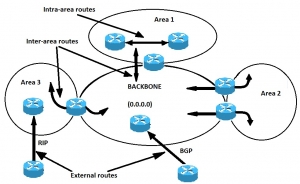
پروتکل OSPF
همانطور که در تصویر بالا می بینید، همه ی نواحی مستقیما به backbone متصل می شوند. در موقعیت هایی نادر که نا حیه ای جدید اضافه می شود که نمی تواند دسترسی فیزیکیِ مستقیم به backbone داشته باشد، باید یک لینک مجازی کانفیگ شود. در بخش بعدی به لینک های مجازی پرداخته می شود. با توجه به شکل انواع گوناگونِ اطلاعات مسیریابی را ملاحظه می کنید. مسیرهایی که درون یک ناحیه ایجاد می شوند (یعنی مقصد مسیر متعلق به همان ناحیه است)، مسیرهای intra-area نامیده می شوند. این مسیرها معمولا با حرف O در جدول IP routing نمایش داده می شوند. مسیرهایی که از یک ناحیه به ناحیه ای دیگر ایجاد می شوند، inter-area یا summary routes خوانده می شوند. علامت گذاری این مسیرها در جدولِ IP routing به صورت O IA است. مسیرهایی که میان نواحی ای با پروتکل های مسیریابی گوناگون (یا پروتکل OSPF گوناگون) ایجاد و به درون شبکه ی OSPF مشخصی وارد می شوند، external route نامیده می شوند. این مسیرها در جدول IP routing با استفاده از حروفِ O E1 یا O E2 نمایش داده می شوند. چندین مسیر به مقصدی یکسان به ترتیب زیر ترجیح داده می شوند:
Intra-area , Inter-area , external E1 , external E2
لینک مجازی
از لینک های مجازی به دو هدف استفاده می شود:
- پیوند دادنِ ناحیه ای که اتصال فیزیکی به backbone ندارد
- ترمیمِ backbone در موقعیت که عدم اتصال به area 0 رخ دهد
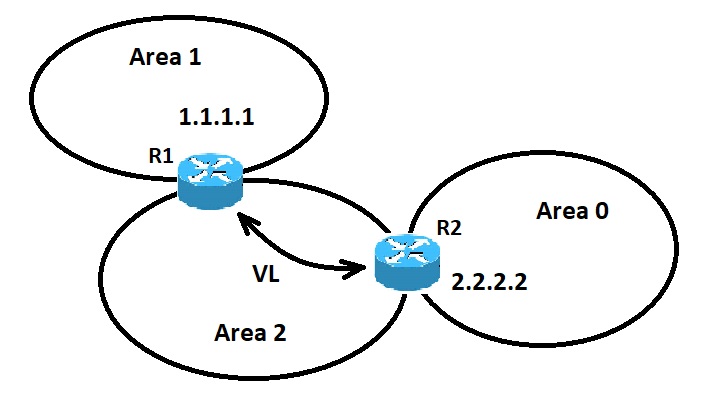
همانطور که گفته شد، از لینک مجازی زمانی استفاده می شود که اتصال فیزیکیِ یک ناحیه به Backbone وجود ندارد. لینک مجازی برای این ناحیه مسیری منطقی را به backbone فراهم می کند. لینک مجازی باید میان دو روتر ABR ایجاد شود که ناحیه مشترکی دارند و یکی از این روترها به ناحیه backbone متصل باشد. در شکل زیر این مسئله نمایش داده شده است:
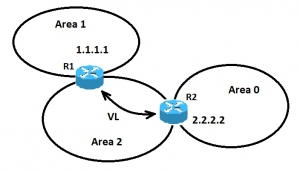
لینک مجازی در پروتکل OSPF
در تصویر بالا، Area 1 اتصال فیزیکیِ مستقیمی به Area 0 ندارد. یک لینک مجازی بین روترهای R1 و R2 باید کانفیگ شود. Area 2 باید به عنوان یک ناحیه ی ترانزیت استفاده شود و روتر R2 نقطه ی ورود به Area 0 باشد. با این روش، روتر R1 و Area 1 اتصالی منطقی به backbone خواهند داشت. به منظور کانفیگ کردنِ یک لینک مجازی در روتر سیسکو، از فرمان <area <area-id> virtual-link <RID بر روی هر دو روتر R1 و R2 استفاده می شود، در اینجا area-id همان ناحیه ترانزیت است که در شکل بالا همان ناحیه ی 2 است. RID همان router-id است. Router-id در پروتکل OSPF معمولا بزرگترین مقدار آدرس IP بر روی اینترفیس فیزیکیِ روتر یا بزرگترین مقدار آدرس loopback بر روی آن است. Router-id تنها در زمان boot یا هر زمانی که پروتکل OSPF شروع به کار می کند، محاسبه می شود. برای یافتنِ router-id از فرمان show ip ospf interface استفاده کنید.
مسیرهای خارجی E1 در برابر E2
مسیرهای خارجی در دو دسته بندیِ E1 و E2 قرار می گیرند. تفاوت میان این دو نوع در روشی است که معیار cost مسیر محاسبه می شود. هزینه ی E2 همیشه هزینه ی خارجی است، یعنی از هزینه های داخل ناحیه برای رسیدن به آن مسیر صرف نظر می شود. هزینه ی E1 مجموعِ هزینه داخلی و خارجی برای رسیدن به یک مسیر به حساب می آید. برای دستیابی به مقصدی یکسان یک مسیر E1 همیشه بر مسیر E2 ترجیح داده می شود.
روترهای همسایه
روترهایی که در ناحیه ای یکسان با یکدیگر مشترک اند، روترهای همسایه یکدیگر در آن ناحیه به شمار می آیند. روترهای همسایه از طریق پروتکل Hello انتخاب می شوند. بسته های Hello به صورت دوره ای با استفاده از آدرس multicast از هر اینترفیس به بیرون فرستاده می شوند. روترها به محض اینکه خود را در لیستِ بسته ی Hello از همسایه خود مشاهده کنند، تبدیل به روترهای همسایه خواهند شد. به این ترتیب ارتباطی دو طرفه تضمین می شود. مذاکرات میان روترهای همسایه تنها بر روی primary address انجام می شود.
در صورتِ موافقت بر روی موارد زیر، دو روتر با یکدیگر همسایه خواهند شد:
- Area-id: دو روتر ناحیه ی مشترکی داشته باشند؛ یک اینترفیس از آنها در ناحیه ای یکسان قرار داشته باشد. البته اینترفیس ها باید متعلق به subnet یکسان باشند و آدرس mask مشابهی داشته باشند.
- Authentication: پروتکل OSPF اجازه خواهد داد که بر روی ناحیه ای مشخص تنظیمات رمز عبور اعمال شود. روترهایی که قصد دارند با یکدیگر همسایه شوند، باید رمز عبور یکسانی را برای ناحیه ای مشخص مبادله کنند.
- فاصله های زمانی بین Hello و Dead: پروتکل OSPF بسته های Hello را بر روی یک ناحیه رد و بدل می کند. این روشی است که برای زنده نگاه داشتن ارتباط میان روترها استفاده می شود تا از حضور همسایه خود در همان ناحیه آگاهی یابد و همچنین یک روتر برگزیده شده (DR) را انتخاب نماید. Hello interval فاصله ی زمانیِ (به ثانیه) میان بسته های hello را مشخص می کند که یک روتر بر روی اینترفیس OSPF خود می فرستد. Dead interval مدت زمانی سپری شده پیش از اعلام از دست دادن روتر موجود در OSPF است که در آن بسته های Hello توسط همسایه دیده نشده اند. در پروتکل OSPF ، این فواصل زمانی باید دقیقا میان دو همسایه یکسان تعریف شده باشد. اگر هر یک از این فاصله های زمانی متفاوت باشد، این روترها در ناحیه ای مشخص به عنوان روترهای همسایه به شمار نخواهند آمد. دستوراتی که برای تنظیم این تایمرها استفاده می شوند: ip ospf hello-interval seconds و ip ospf dead-interval seconds
- Stub area flag: روترها برای اینکه با یکدیگر همسایه باشند باید بر روی stub area flag درون بسته های Hello به توافق برسند. تعریف stub area بر فرآیند انتخاب همسایه تاثیر می گذارد (پروتکل OSPF اجازه خواهد داد که نواحی معینی به عنوان stub area تنظیم شوند. به شبکه های خارجی اجازه داده نخواهد شد که درون ناحیه stub بسته ها را Flood کنند. مسیریابی از این ناحیه به خارج از آن مبتنی بر یک مسیر پیش فرض است. تنظیم ناحیه Stub سایز پایگاه داده مرتبط با توپولوژیِ درون یک ناحیه را کاهش می دهد).
Adjacency
پس از فرآیند انتخاب همسایه، گام بعدی Adjacency است. روترهای adjacent روترهایی هستند که از مبادله ی ساده بسته hello فراتر می روند و به سمت فرآیند مبادله ی پایگاه داده پیش می روند. به منظور کاستن از حجم مبادله ی اطلاعات در ناحیه ای خاص، پروتکل OSPF یک روتر را به عنوان Designated Router) DR) و روتر دیگری را به عنوان Backup Designated Router) BDR) انتخاب می کند. روتر BDR به عنوان مکانیزم پشتیبان به هنگام از دست دادن روتر DR استفاده می شود. ایده نهفته در پس این روش این است که روترها یک نقطه ارتباط مرکزی برای تبادل اطلاعات داشته باشند. به جای اینکه هر روتر با هر روتر دیگر در آن ناحیه دو به دو بروزرسانی ها را مبادله کنند، هر روتر اطلاعات را تنها با روتر DR و BDR مبادله می کند. روترهای DR و BDR این اطلاعات را به دیگران منتقل می کنند. از لحاظ ریاضی این روش باعث خواهد شد که هزینه مبادله ی اطلاعات از (O(n*n به (O(n کاهش یابد، در اینجا n تعداد روترهایی است که در این ناحیه قرار دارند.
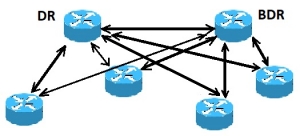
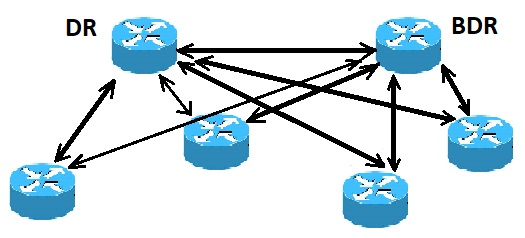
روتر DR و BDR در پروتکل OSPF
در تصویر بالا همه ی روترها در یک ناحیه مشترک قرار گرفته اند. به علت مبادله ی بسته های Hello ، یک روتر به عنوان روتر DR و روتری دیگر به عنوان BDR انتخاب شده است. هر روتر در این ناحیه (که پیش از این همسایه روتری دیگر شده است) تلاش می کند که با روتر DR و DBR یک adjacency ایجاد کند.
انتخاب DR
انتخاب DR و BDR از طریق پروتکل hello انجام می شود. بسته های Hello از طریق بسته های multicast در هر ناحیه مبادله می شوند. روتری که بیشترین OSPF priority را در یک ناحیه دارد به عنوان روتر DR در آن ناحیه انتخاب می شود. فرآیند مشابهی نیز برای انتخاب روتر BDR تکرار می شود. در صورت تساویِ اولویت ها در روترها، روتری که بیشترین RID را دارد، پیروز خواهد شد. اولویت OSPF برای اینترفیس به صورت پیش فرض برابر با 1 است.
مقدار priority برابر با 0 ، نشان دهنده ی آن است که آن اینترفیس به عنوان DR یا BDR انتخاب نشده است. در تصویر زیر فرآیند انتخاب DR را مشاهده می کنید:
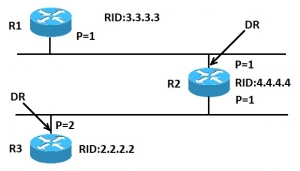
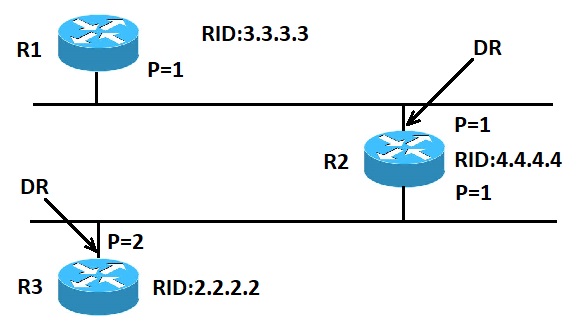
انتخاب روتر DR در پروتکل OSPF
در تصویر بالا روترهای R1 و R2 اولویت های یکسانی دارند، اما RID مربوط به روتر R2 بیشتر است. در نتیجه در آن ناحیه روتر R2 به عنوان DR انتخاب می شود. روتر R3 نسبت به روتر R2 از اولویت بالاتری برخوردار است، در نتیجه در آن ناحیه روتر R3 به عنوان DR انتخاب می شود.
ایجاد Adjacency
فرآیند ایجاد Adjacency پس از اتمام چندین مرحله انجام می گیرد. روترهایی که در مجاورت (adjacent) یکدیگر قرار می گیرند، پایگاه داده ی یکسانی دارند. وضعیت هایی که یک اینترفیس می پیماید تا در مجاورت روتر دیگری قرار بگیرد، به طور خلاصه در زیر آورده شده است:
- Down: هیچ اطلاعاتی از هیچ دستگاهی در آن ناحیه دریافت نمی شود.
- Attempt: این وضعیت بیان می کند که اخیرا هیچ اطلاعاتی از روتر همسایه دریافت نشده است. باید با ارسال بسته های Hello برای برقراری ارتباط با روتر همسایه تلاش نماید.
- Init: اینترفیس، یک بسته Hello ورودی از طرف همسایه را تشخیص داده است اما هنوز ارتباطی دو طرفه ایجاد نشده است.
- Two-way: ارتباط دو طرفه با روتر همسایه برقرار است. در این زمان، روتر خود را در بسته های Hello ورودی از طرف همسایه مشاهده کرده است. در پایان این مرحله، انتخاب DR و BDR انجام شده است. در پایان مرحله ی 2way ،روترها تصمیم خواهند گرفت که یک Adjacency را ایجاد نمایند یا خیر. این تصمیم بر این اساس استوار است که کدام یک از روترها DR یا BDR است یا اینکه لینک point-to-point است یا virtual.
- Exstart: روترها شماره هایی ترتیبی را برای بسته های مبادله اطلاعات ایجاد می کنند. این شماره های ترتیبی تضمین خواهد نمود که روترها همیشه بروزترین اطلاعات را در اختیار دارند. بک روتر به عنوان primary و روتر دیگر secondary خواهد شد. روتر primary از روتر secondary اطلاعات را جمع آوری می کند.
- Exchange: روترها تمامیِ LSDB خود را از طریق ارسال بسته های DBD ترسیم می کنند. در این وضعیت بسته ها می توانند به اینترفیس های دیگر بر روی روتر flood شوند.
- Loading: در این وضعیت، روترها در حال به پایان رساندن تبادل اطلاعات هستند. روترها یک درخواست link-state و یک لیست ارسال مجدد link-state را ایجاد می کنند. هر اطلاعاتی که ناقص یا منقضی به نظر برسد در لیست درخواست قرار می گیرد. هر بروزرسانی ای که ارسال شود تا زمانی که Ack مرتبط با آن دریافت شود، در لیست ارسال مجدد قرار می گیرد.
- Full: در این وضعیت، Adjacency کامل شده است. روترهای همسایه با یکدیگر به طور کامل adjacent شده اند. روترهای Adjacent پایگاه داده link-state مشابهی خواهند داشت.
نکاتی برای طراحیِ پروتکل OSPF
در اسنادِ رسمی مرتبط با پروتکل OSPF خط مشی ای برای تعداد روترها در یک ناحیه یا تعداد همسایه ها در هر بخش داده نمی شود و یا گفته نمی شود که بهترین روش یرای طراحی معماری این شبکه چیست. افراد گوناگون رویکردهای متفاوتی به طراحی شبکه با پروتکل OSPF دارند. مهمترین چیزی که باید به خاطر سپرد این است که هر پروتکلی می تواند تحت فشارها به شکست بیانجامد. در ادامه لیستی از مسائلی که باید به آنها توجه نمود، آورده شده است.
تعداد روترها در هر ناحیه
حداکثر تعداد روترها در هر ناحیه به چندین فاکتور وابسته است، که شامل موارد زیر می شود:
- چه نوعی از Area را در اختیار دارید؟
- چه نوعی از توان CPU را در آن ناحیه در اختیار دارید؟
- چه نوعی از مدیا استفاده می شود؟
- آیا پروتکل OSPF در مود NBMA (در این مود بسته های Hello به روترهای همسایه broadcast نمی شوند، بلکه روتر این بسته ها را تنها به همسایه هایی که خواهان دریافت آن هستند، ارسال می کند) اجرا می شود؟
- آیا شبکه NBMA شما مش بندی شده است؟
- آیا تعداد LSA های خارجی زیادی در شبکه دارید؟
- آیا مسیریابی میان نواحی به خوبی انجام می شود؟
تعداد همسایه ها
همچنین تعداد روترهایی که به شبکه ی lan یکسانی متصلند، از اهمیت بالایی برخوردار است. هر شبکه lan یک روترِ DR و BDR دارد که همسایگی را برای تمامی روترهای دیگر ایجاد می کنند. هر چه تعداد همسایگان کمتری بر روی LAN وجود داشته باشد، تعداد همسایگی های کمتری توسط رورترهای DR یا DBR باید ایجاد شود. این مسئله وابسته است به قدرتی که روتر شما دارد. شما همیشه تواناییِ تغییر OSPF priority را دارید تا به واسطه آن روتر DR را انتخاب نمایید. همچنین از داشتن بیش از یک روتر DR در یک ناحیه پرهیز کنید. اگر انتخاب روتر DR بر مبنای بیشترین مقدار RID باشد، درنتیجه به صورت تصادفی یک روتر باید به عنوان DR در سراسر نواحی ای که به آن متصل است، انتخاب شود. این روتر باید نسبت به دیگر روترهای بیکار، کار مضاعفی را انجام دهد.
تعداد نواحی به ازای هر روتر ABR
روتر ABR نسخه ای از پایگاه داده ی مربوط به تمامی نواحی که به آنها خدمات می دهد را ذخیره می کند. به طور مثال، اگر روتری به 5 ناحیه متصل باشد، باید لیستی از 5 پایگاه داده ی مختلف را در خود نگهداری نماید. تعداد ناحیه ها به ازای هر روتر ABR ، مقداری است که به فاکتورهای بسیاری وابستگی دارد که شامل نوع ناحیه (normal ، stub ، NSSA) ، قدرت CPU روتر ABR ،تعداد مسیرها به ازای هر ناحیه و تعداد مسیرهای خارجی به ازای هر ناحیه می شود. به همین علت تعداد نواحی دقیقی به ازای هر روتر ABR توصیه نمی شود.
جمع بندی
پروتکل OSPF ، پروتکلی متن باز با عملکرد بالا را در اختیار شما می گذارد که به چندین با vendor های گوناگون اجازه برقراری ارتباط از طریق پروتکل TCP/IP را می دهد. پروتکل OSPF پروتکل مسیریابیِ قوی و سریعی است که در صورتی که به درستی کانفیگ شود، با قدرت در شبکه های بزرگ عمل می نماید.
برخی از ویژگی های OSPF عبارتند از : سرعت، convergence، VLSM ، احراز هویت، بخش بخش سازی سلسله مراتبی و … که برای مدیریت شبکه های پیچیده و بزرگ به کار برده می شوند.